Project Details
You are a business analyst consultant and your client is a new movie production company looking to make a new movie. The client wants to make sure it’s successful to help make a name for the new company. They are relying on you to help understand movie trends to help inform their decision making. They’ve given you guidance to look into three specific areas:
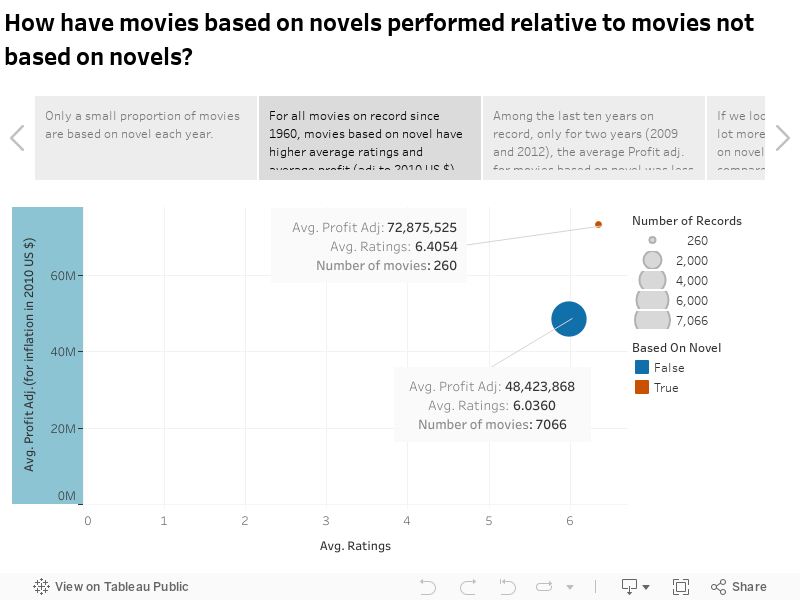
Question 1: How have movies based on novels performed relative to movies not based on novels?
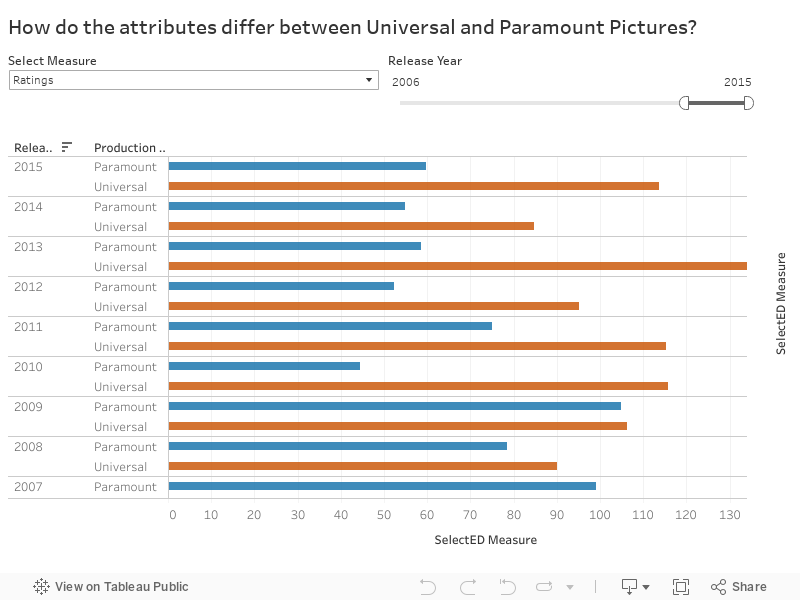
Question 2: How do the attributes differ between Universal Pictures and Paramount Pictures?
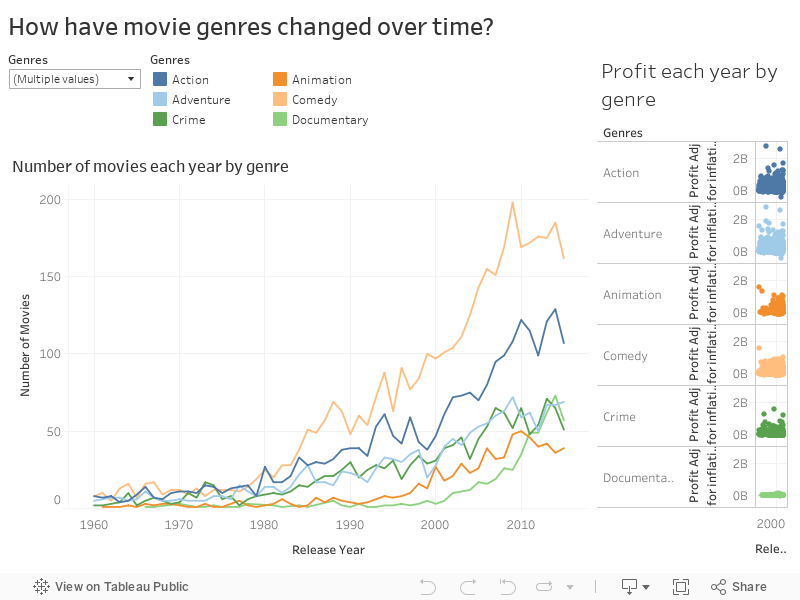
Question 3: How have movie genres changed over time?
In this blog post, I will clean the data and get the dataset ready for Tableau visualization. In the second part of the post, I will attempt to answer these questions using Tableau Dashboard and Stories.
Source:- TheMovieDB
Getting Started¶
# Import the libraries needed
import pandas as pd
import numpy as np
import re
import calendar
The original data used for the analysis can be downloaded from the following link. When I tried to open the file directly using pandas read_csv module, I ran into following error- "UnicodeDecodeError: 'utf-8' codec can't decode byte 0xcc in position 12: invalid continuation byte". So I had to open the file in Sublime Text and save it with utf-8 encoding. This allowed me to open the file using pandas read_csv module.
# Load the data into a pandas dataframe
movies = pd.read_csv("data/movies.csv")
movies.head()
Data clean up¶
If we look at the dataset the information needed to answer the questions isn't readily available. We need to do some preprocessing on relevant columns to dig out the information needed to answer the questions.
We will start by fixing the columns that pertain to the question we are trying to address.
Question 1: How have movies based on novels performed relative to movies not based on novels?
To address this question we need to find movies that are based on novels. This information is primarily available in keywords column and in tagline column. Instead of fixing the genres column for the entire dataset, I select few columns and make a subset of data to work with it.
movies_novels = movies[["id", "original_title", "keywords", "tagline"]].reset_index(drop = True)
movies_novels.head(10)
As I went through the keywords column, I noticed that there are multiple phrases that could tell whether a movie is based on novel - 'based on novel', 'based on graphic novel', 'inspired by novel' etc. In order to list all of the possible phrases we could be dealing with, I write a regular expression script to search for the first occurrence of phrase with 'novel' in each row. The function returns either the phrase with 'novel' in it or None.
def find_novel_from_keywords(keywords):
try:
match = re.search("(\|{0,1}[\w\s]*novel[\w\s]*\|{0,1})", keywords)
if match:
return match.group(0)
else:
return None
except TypeError:
return None
phrases_with_novel = set()
for text in set(movies_novels["keywords"].tolist()):
pattern = find_novel_from_keywords(text)
phrases_with_novel.add(pattern)
print(phrases_with_novel)
Hmm! there are several phrases with 'novel' in it, but only three phrases tell us if a movie is based on a novel. The three phrases are - 'based on novel', 'based on graphic novel', and 'inspired by novel'. Next, we will create a column based_on_novel_0 that looks for those three phrases from keywords column and returns True if the movie is novel based.
def find_novel_based_movie(keywords):
try:
match1 = re.search("(\|{0,1}based[\w\s]*novel\|{0,1})", keywords)
match2 = re.search("(\|{0,1}inspired[\w\s]*novel\|{0,1})", keywords)
if match1 or match2:
return True
else:
return False
except TypeError:
return None
movies_novels["based_on_novel_0"] = movies_novels["keywords"].apply(find_novel_based_movie)
movies_novels.head()
It is also quite likely that information for whether a movie is based on novel is in tagline column. Let us search tagline column for any phrase with novel in it.
def find_novel_from_tagline(tagline):
try:
match = re.search("(.*novel.*)", tagline)
if match:
return match.group(0)
else:
return None
except TypeError:
return None
phrases_with_novel_1 = set()
for text in set(movies_novels["tagline"].tolist()):
pattern = find_novel_from_tagline(text)
phrases_with_novel_1.add(pattern)
print(phrases_with_novel_1)
There were four movies based on novel for which the information was present in tagline column. Next, we will create a column based_on_novel_1 that looks for those phrases from tagline column and returns True if the movie is novel based.
def find_novel_based_movie_1(tagline):
try:
match = re.search("(.*novel.*)", tagline)
if match:
return True
else:
return False
except TypeError:
return None
movies_novels["based_on_novel_1"] = movies_novels["tagline"].apply(find_novel_based_movie_1)
movies_novels.head()
We are only interested in finding whether a movie is based on novel. We are not concerned whether that information comes from keywords column or tagline column. We will create a single column based_on_novel from based_on_novel_0 and based_on_novel_1. At the same time, we will now drop columns we don't need anymore.
movies_novels["based_on_novel"] = movies_novels["based_on_novel_0"] + movies_novels["based_on_novel_1"]
movies_novels.drop(["keywords", "tagline", "based_on_novel_0", "based_on_novel_1"], axis = 1, inplace = True)
movies_novels.head()
We will now convert the based_on_novel column from integers to boolean. Before that, we need to check the different integer values that are there in the column beside 0 and 1. It is quite likely that information for movie based on a novel is present on both the columns- keywords and tagline. As a result, some of the values for based_on_novel might be two. Let's check that out.
print(movies_novels["based_on_novel"].unique())
movies_novels[movies_novels['based_on_novel'] == 2]
movies.loc[movies['original_title'] == "Airport", ["original_title", "keywords", "tagline"]]
int_to_bool = {0: 'False', 1: 'True', 2: 'True'}
movies_novels['based_on_novel'] = movies_novels['based_on_novel'].apply(int_to_bool.get)
movies_novels.head()
Now we have our new column based_on_novel in a format that can be used for Tableau visualization. Let's drop the keywords and tagline columns in the original dataset and merge the movies_novels data subsets with the original movie dataset using id and original_title.
movies.drop(["keywords", "tagline"], axis = 1, inplace = True)
# We will use the merge function in pandas to merge the scraped data subsets and original movies dataset.
# The merge function in pandas is similar to join in SQL.
movies = pd.merge(movies,
movies_novels,
how = "left",
left_on=["id", "original_title"],
right_on=["id", "original_title"])
movies.head()
Question 2: How do the attributes differ between Universal Pictures and Paramount Pictures?
To answer this question we need to tidy up the production_companies column. Each row of production_companies column contains several production companies separated by | and there can be a maximum of five companies. We are interested in finding out whether a movie was produced by Universal Pictures, or Paramount Pictures, or None.
movies_production_companies = movies[["id", "original_title", "production_companies"]].reset_index(drop = True)
movies_production_companies.head()
As I skimmed through the production_companies column, I noticed that Universal Studios was not named consistently - Universal Studios, Universal Pictures, Universal etc. In order to find out all the possible names of Universal Studios we could be dealing with, I wrote a script to search for the first occurrence of phrase with 'Universal' in each row. The function returns either the phrase with word Universal in it or None.
def find_Universal(production_company):
try:
match = re.search("(\|{0,1}[\w\s]*Universal[\w\s]*\|{0,1})", production_company)
if match:
return match.group(0)
else:
return None
except TypeError:
return None
words_with_Universal = set()
for text in set(movies_production_companies["production_companies"].tolist()):
pattern = find_Universal(text)
words_with_Universal.add(pattern)
print(words_with_Universal)
Huh! there are several phrases with Universal in it. I googled to figure out if these were all divisions of the same company. The wikipedia page states - "Universal Pictures (also referred to as Universal Studios or simply Universal) is an American film studio owned by Comcast through the Universal Filmed Entertainment Group division of its wholly owned subsidiary NBCUniversal." An extensive search revealed that these are all part of American multinational media conglomerate NBCUniversal.
I also wanted to go ahead and check if it was similar case for Paramount Pictures. I wrote a similar script to search for the first occurrence of phrase with 'Paramount' in each row.
def find_Paramount(production_company):
try:
match = re.search("(\|{0,1}[\w\s]*Paramount[\w\s]*\|{0,1})", production_company)
if match:
return match.group(0)
else:
return None
except TypeError:
return None
words_with_Paramount = set()
for text in set(movies_production_companies["production_companies"].tolist()):
pattern = find_Paramount(text)
words_with_Paramount.add(pattern)
print(words_with_Paramount)
As stated in Wikipedia - "Paramount Pictures Corporation (also known as Paramount Pictures and simply Paramount) is an American film studio based in Hollywood, California, that has been a subsidiary of the American media conglomerate Viacom since 1994." These above-listed names are all subsidiaries of the same company.
Now we can write some code to tag all the companies with Universal in their names as Universal and all the companies with Paramount in their names as Paramount, and neither as None for our purpose. To do this, I used a regular expression that searches for the first occurrence of Universal or Paramount in each row of production_companies column.
def find_Universal_or_Paramount(production_company):
try:
universal = re.search("(\|{0,1}[\w\s]*Universal[\w\s]*\|{0,1})", production_company)
paramount = re.search("(\|{0,1}[\w\s]*Paramount[\w\s]*\|{0,1})", production_company)
if universal:
return "Universal"
elif paramount:
return "Paramount"
else:
return None
except TypeError:
return None
# Transform the original 'production_companies' to only keep relevant information
movies["production_companies"] = movies["production_companies"].apply(
find_Universal_or_Paramount)
# We can see that the production_companies column has been transformed in the original dataset
movies.head()
While we are here, let us also extract day, month, and day of the week information from the date column. We will create these three new columns in the original movies dataset itself. These attributes can be used for exploring the seasonal effect on movie's performance.
movies["release_month"] = pd.DatetimeIndex(movies["release_date"]).month
movies["release_month"] = movies["release_month"].apply(lambda x: calendar.month_abbr[x])
movies["release_day"] = pd.DatetimeIndex(movies["release_date"]).day
movies["release_dayofweek"] = pd.DatetimeIndex(movies["release_date"]).weekday_name
movies.head()
We will also calculate two important metrics that we will use later for Tableau visualization.
movies["profit"] = movies["revenue"] - movies["budget"]
movies["profit (%)"] = (movies["revenue"] - movies["budget"])*100/movies["budget"]
movies["profit_adj"] = movies["revenue_adj"] - movies["budget_adj"]
movies.head()
Write the dataframe to csv file for Tableau visualization.
movies.to_csv('data/movies_cleaned.csv',
index = False)
Question 3: How have movie genres changed over time?
Problem: The genres column consists of multiple genres in the same cell separated by "|". To tidy this data up, we need to have one genre per row associated with their respective id. Instead of fixing the genres column for the entire dataset, I select few columns and make a subset of data to work with it.
movies_genres = movies[["id", "original_title", "genres"]].reset_index(drop = True)
movies_genres.head()
First, we separate multiple genres associated with each movie into multiple columns. We know from the data specifications that there can be a maximum of five genres for each movie, so we will separate the genres column into five columns.
movies_genres[['genre1', 'genre2', 'genre3', 'genre4', 'genre5']] = movies_genres['genres'].str.split(
"|", expand = True)
del movies_genres['genres']
The genres variable is now spread out across multiple columns and the data is in wide format. As a final tidying step, we will use pandas melt function to convert the dataset from wide to tall format.
movies_genres = pd.melt(movies_genres, id_vars = ["id", "original_title"],
value_name = "genres", var_name = "genre_n")
# Drop rows with no values in genres column
movies_genres.dropna(axis = 0, subset = ['genres'], inplace = True)
movies_genres.head()
movies[movies["original_title"] == "3 Ninjas"]
# Delete the original genres column in the movies dataset
del movies["genres"]
# Merge the dataframes
movies_cleaned_genres = pd.merge(movies,
movies_genres,
how = "right",
left_on=["id", "original_title"],
right_on=["id", "original_title"])
# Write the dataframe to csv file for Tableau visualization.
movies_cleaned_genres.to_csv('data/movies_cleaned_genres.csv',
index = False)
Tableau Data Visualization¶
%%HTML
%%HTML
%%HTML
%%HTML

References¶
1) Scraping for craft beers
2) Tidy data in Python
3) Data Visualization in Tableau
4) Tableau training videos
5) Sparklines
6) Slopegraphs
7) Quadrant chart
8) KPIs and Sparklines
Comments
comments powered by Disqus